DeepMind เผยรายละเอียดการทำงานของ AlphaZero ที่ชนะโปรแกรมแชมป์โลกทั้ง โกะ, หมากรุก และหมากรุกญี่ปุ่น
DeepMind เผยแพร่รายละเอียดเพิ่มเติมใน The Journal Science เกี่ยวกับการพัฒนา AI ตัวใหม่ AlphaZero ที่พัฒนาต่อจาก AlphaGo ให้สามารถเรียนรู้พัฒนาด้วยตนเองได้ นอกจากการเล่นโกะ มาสู่การเล่นหมากรุก และหมากรุกญี่ปุ่น (โชงิ) โดยสามารถเอาชนะบ็อตที่เก่งที่สุดในโลกได้ จากการเรียนรู้เองในเวลาไม่นาน
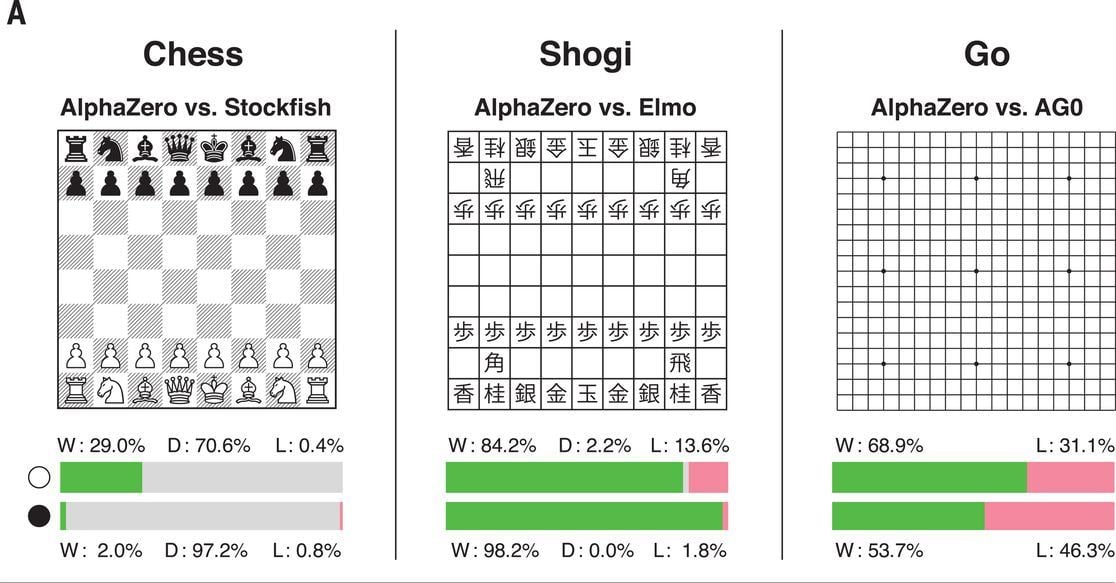
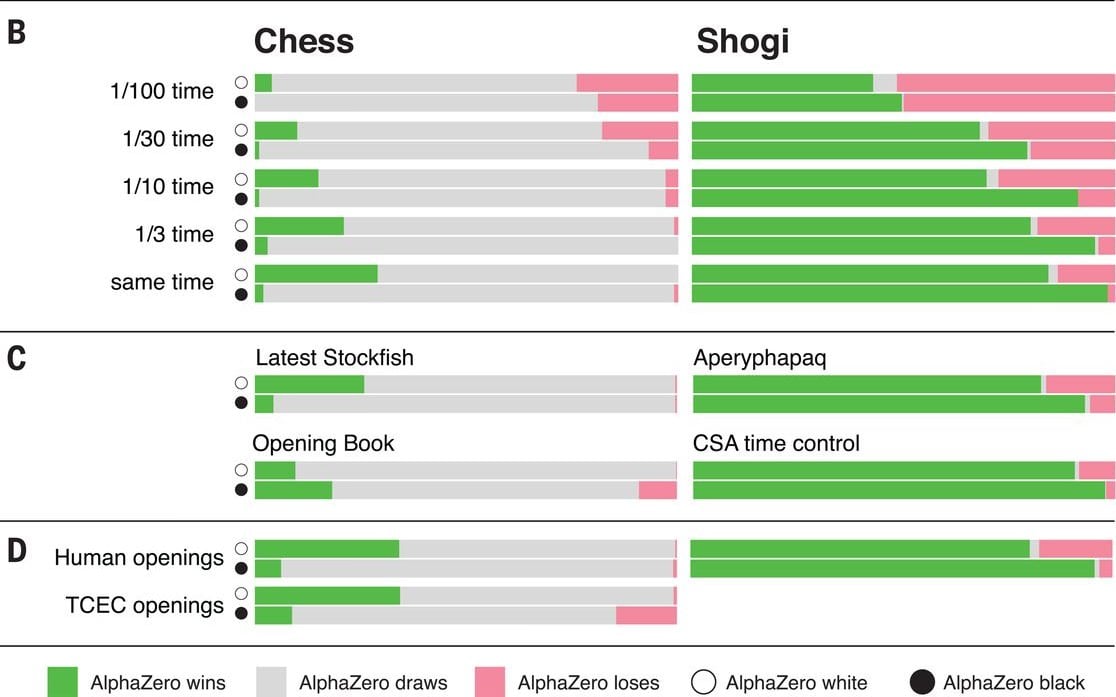
โดยผลการแข่งขันนั้น AlphaZero สามารถเอาชนะหมากรุกกับ StockFish ได้ 155 เกม แพ้ 6 นอกนั้นเสมอจากทั้งหมด 1,000 เกม โดยใช้เวลาเรียนรู้ทั้งหมด 9 ชั่วโมง ส่วนหมากรุกญี่ปุ่นใช้เวลาเรียนรู้ 12 ชั่วโมง สามารถชนะโปรแกรม Elmo ได้ 91.2% และสุดท้ายในเกมโกะ เอาชนะ AlphaGo ได้ 61% ใช้เวลาเรียนรู้ 13 วัน
ข้อมูลน่าสนใจเพิ่มเติมเกี่ยวกับการประมวลผลของ AlphaZero นั้น ใช้รูปแบบการค้นหาวิธีที่ดีที่สุดแบบ Monte Carlo Tree Search ด้วยพลังของ 5,000 Tensor Processing Units (TPU) ซึ่งความสามารถของ 1 TPU เทียบได้กับความสามารถในการจัดการรูปใน Google Photos ได้ 100 ล้านรูปต่อวัน
ที่มา: The Next Web
from Blognone https://www.blognone.com/node/106909
via IFTTT
